用 RxJava 处理网络数据和本地缓存这个话题大家肯定听过好多遍了,但今天这里还有点新花样:高级缓存。什么叫高级缓存?我得向大家坦白,题目中的“高级”其实只是为了吸引大家点进来,内容有一定综合性,希望大家喜欢。
1,先理解问题
首先我们当然需要理解清楚问题:
本地缓存了大量的用户信息,放在一张数据库的表中,当我们拿着一个 id 列表批量获取用户信息时,我们需要首先从数据库中查询这些用户,这里就很可能有一部分数据命中了缓存,有一部分数据没有命中,对于后者,我们需要请求一个批量获取用户信息的 API,然后把网络数据保存到数据库中,最后我们把两批数据合并起来返回给业务层。
问题描述应该还算清晰,但这个需求确实算是比较复杂了,相比于典型的“先展示本地数据,再展示网络数据”或者“本地缓存命中,就不请求网络”,区别不言而喻。
2,理清处理过程
理解问题之后,一定不要急着开始写代码,因为很可能写到一半我们就会发现,这么写好像不行,于是推倒重来,而且很可能会重复好几遍。
道理都懂,但真正做起来还是挺难的,到现在我都还忍不住,而且依然会出现过早开始编码的情况,好的习惯仍需继续努力培养 :)
问题描述就比较清晰,我们只需要稍加整理即可,一图胜千言:
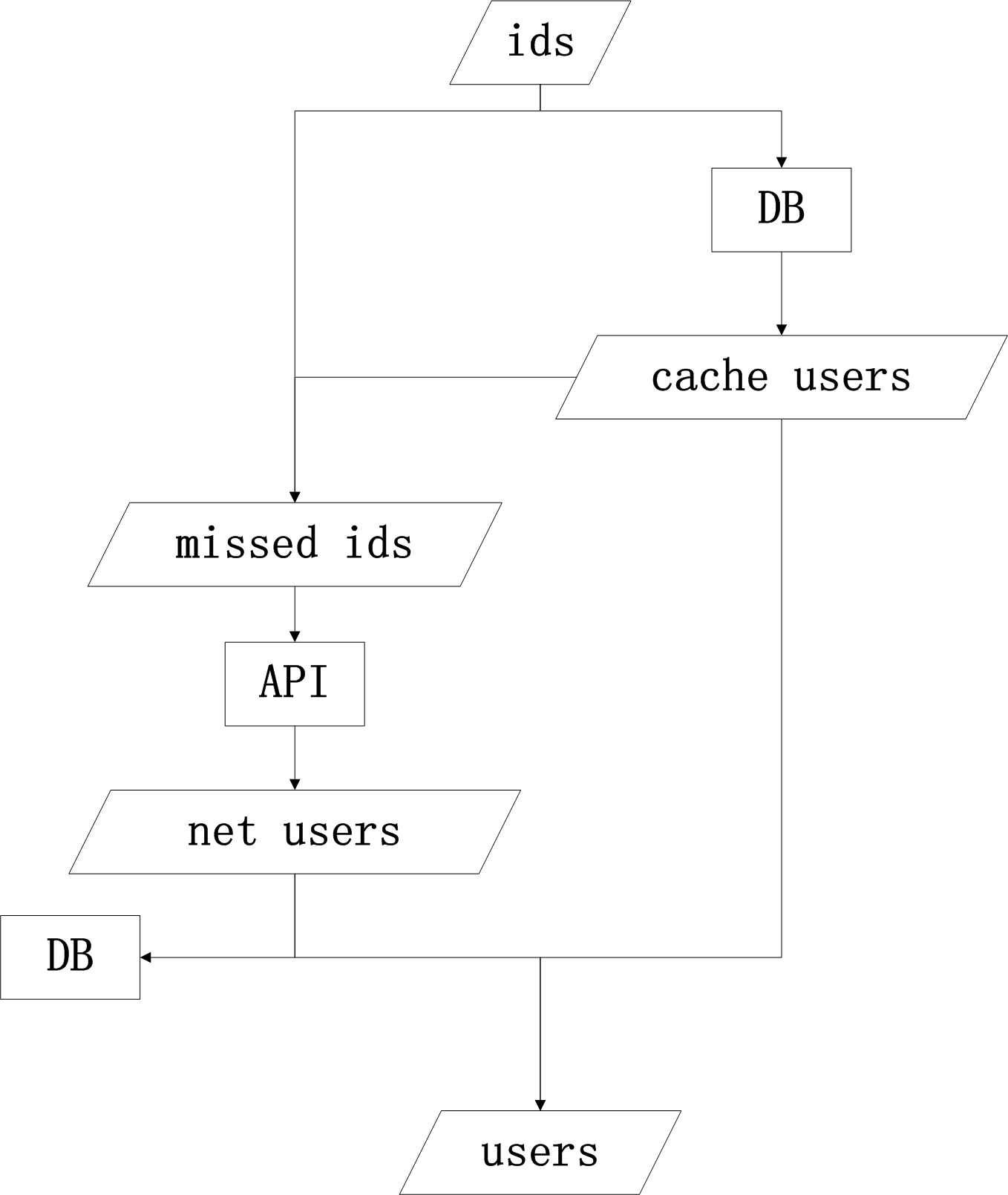
我们可以很清晰地看到,左右两边分为两个数据流,我们最后需要合并它们,但在中间它们又有一些交互,尤其是 cache users,开出一个新分支,经过一系列处理之后,又和自己合并。
3,动手实现
这里主要展示核心代码,用到了 Java8 lambda 表达式,不熟悉的朋友要先看看 Java8 lambda 相关的内容。
Observable<List<User>> batchUserInfoUnordered(long[] ids) {
Observable<Pair<List<User>, long[]>> cacheResult =
Observable.defer(() -> { // 1
List<User> cached = mUserDbAccessor.getIn(ids); // 2
if (cached.size() == ids.length) {
return Observable.just(Pair.create(cached, EMPTY)); // 3
}
long[] missed = new long[ids.length - cached.size()];
long[] hits = extractids(cached);
Arrays.sort(hits);
int pos = 0;
for (long id : ids) {
if (Arrays.binarySearch(hits, id) < 0) { // 4
missed[pos] = id;
pos++;
}
}
return Observable.just(Pair.create(cached, missed));
});
Observable<List<User>> hits = cacheResult.map(pair -> pair.first); // 5
Observable<List<User>> missed = cacheResult
.flatMap(pair -> { // 6
if (pair.second == EMPTY) { // 7
return Observable.just(Collections.<User>emptyList());
}
return mUserInfoApi.multipleUserInfo(pair.second); // 8
})
.doOnNext(mUserDbAccessor::put); // 9
return Observable.zip(hits, missed, (local, remote) -> { // 10
List<User> merged = new ArrayList<>(local.size() + remote.size());// 11
merged.addAll(local);
merged.addAll(remote);
return merged;
});
}
代码看起来非常优雅,如行云流水一般,对不对?其实写出这段代码也还是花了一番心思。下面稍微讲解一下:
- 我们用
defer操作符来把一个同步的函数调用包装为一个Observable。 mUserDbAccessor封装了数据库访问的代码,ORM/DAO 什么的,总觉得不够酷 :) 这里使用SELECT IN来进行选择,值得一提的是,SQL 语句的构造,有多少个参数,就需要多少个参数占位符(?),否则就选不出来。EMPTY是一个空数组常量,表示没有缓存缺失。- 如何找出缺失的 id 列表?这里我用了一个比较简单的算法,先把命中列表排序,再遍历原 ids 列表,从命中列表中进行二分查找,没找到就说明缺失了,复杂度 O(n * log n)。
- 我们利用
map操作符,把Pair中的User列表取出来。 - 我们再利用
flatMap操作符,把Pair中的缺失列表取出并转化为发出User列表的Observable。 - 这一步很重要,在缓存没有缺失的时候,可能有的朋友会直接返回
Observable.empty(),理由也很简单,没有网络数据嘛,当然就是empty。但这里我们需要考虑第 10 步中的zip操作符,如果这里我们返回empty,那zip的将不会有输出! - 我们调用 API 批量获取缺失的数据。
- 我们把网络数据放入到数据库中。
- 我们用
zip操作符,把缓存分支和网络分支合并起来,zip的机制就是所有来源都有了数据,才把它们合并起来(另外还有一个操作符combineLatest,它是每当有一个来源有了数据,就收集所有来源的最新数据进行合并)。 - 最后我们进行合并操作,这里有一个小技巧,我们已知了最终数组的大小,就可以提前预分配了,尽管这里不会是性能瓶颈,但是几乎零编码成本的提升,何乐而不为?
正如函数名中的 Unordered 所言,这里我们并不会保证结果与请求顺序的一致性,如果需要保证,那也很简单,最后再加一个 map 操作即可。
写了这么大一段优雅的代码,如果是你,会不会迫不及待想测试一下效果了呢?肯定是。但怎么测试呢?是接着编写业务层、UI 层的代码,(手工)集成测试,还是先写一个单元测试呢?
其实只要想到这个问题,答案应该就很明确了,既然无论手工还是测例,总归是要测试的,那我们何不稍微多花一点工夫,编写单元测试呢?此外,还要再编写一大堆业务/UI 代码的话,我们等得未免也太久。而且,永远不要相信你的眼睛,一切用代码说话,手工黑盒测试通过了,根本不能保证内部逻辑符合预期,尤其是上面这么复杂的逻辑。最后,没有单元测试覆盖的重构,验证成本呈指数增长。
4,赖不掉的测试
既然赖不掉,那我们就写个同样漂亮的测试。
鉴于即便我已经写过好多测试了,但是配置项目的测试依赖依然遇到了问题,所以这里我还是把依赖贴出来:
testCompile 'junit:junit:4.12'
testCompile 'org.mockito:mockito-core:2.0.71-beta'
junit 依赖就不用说了,新建安卓项目默认就添加的这个依赖,mockito 是一个进行 mock 的框架,除了能 mock,还能 verify,很好很强大。另外还有一点值得一提的是,不要同时依赖 mockito 和 dexmaker,它们不能很好地一起工作。只添加这两个依赖,测例就可以编写和运行了。
接下来看代码之前,不熟悉 junit 和 mockito 的朋友一定要先看看文档,不然会云里雾里。
@Rule
public MockitoRule mMockitoRule = MockitoJUnit.rule(); // 1
@Mock
UserInfoApi mUserInfoApi; // 2
@Mock
UserDbAccessor mUserDbAccessor;
@Test
public void batchUserInfoUnordered() {
long[] uids = new long[]{1, 2, 3};
final User user = mGson.fromJson(MOCK_USER, User.class);
when(mUserDbAccessor.getIn(uids)) // 3
.thenReturn(Collections.emptyList());
when(mUserInfoApi.multipleUserInfo(uids))
.thenReturn(Observable.just(Collections.singletonList(user)));
UserRepo userRepo = new UserRepo(mUserInfoApi, mGson, mUserDbAccessor);
TestSubscriber<List<UserInfoModel>> testSubscriber = // 4
new TestSubscriber<>();
userRepo.batchUserInfoUnordered(uids).subscribe(testSubscriber);
testSubscriber.awaitTerminalEvent();
testSubscriber.assertNoErrors();
testSubscriber.assertCompleted();
testSubscriber.assertValue(Collections.singletonList(user)); // 5
verify(mUserInfoApi, times(1)).multipleUserInfo(uids); // 6
verifyNoMoreInteractions(mUserInfoApi);
verify(mUserDbAccessor, times(1)).getIn(uids); // 7
verify(mUserDbAccessor, times(1))
.put(Collections.singletonList(user));
verifyNoMoreInteractions(mUserDbAccessor);
}
测试代码千万不能写得丑,不然我们只会更讨厌写测试代码,不过我自认为上面的测试代码也还是非常漂亮的。
先讲一下测试逻辑:我们配置数据库缓存返回空,即全部缺失,再配置 API 返回一个 User。那我们就应该验证:我们最终拿到了 API 返回的那个 User、并且进行了一次数据库查询、进行了一次 API 调用、进行了一次数据库保存。
下面看一下具体的代码:
@Rule这个注解是让测试运行之前能进行一些初始化,例如 2 中的初始化 mock,初始化工作由 mockito 完成。我们也可以用@RunWith注解,使用 mockito 的 runner,但这就让我们无法使用其他的 runner 了。这一点类似于 composition over inheritance,让用户可以更加灵活,很好。- 我们利用
@Mock注解,让 mockito 替我们初始化 mock,简化代码。 - 配置 mock 的行为时,一定要注意参数的匹配,例如我们这里将要使用
{1, 2, 3}这个数组,那如果用any()就无法匹配,最好是传什么参数,就直接用参数进行匹配。 - RxJava 业界良心,为我们提供了
TestSubscriber便于测试,非常棒。 - 我们首先验证我们确实拿到了 API 返回的 User。
- 再验证我们只调用了一次 API,而且没有调用其他任何接口。
- 最后我们再验证只进行了一次数据库查询、一次数据库保存,没有其他任何调用。
怎么样,逻辑非常严密吧?想想如果我们等到 UI 写完之后手动测试,能测到哪一步?那时我们只能验证第 5 点,6 确实可以通过抓包验证,7 呢?给数据库访问加 log 然后看 log?NO NO NO!工程师不应该这么傻。我们这里只需要一个测例,就完全 cover 了所有的测试点,完美。
5,很遗憾,测试失败
没有想象中的一次通过,我们“正常地”失败了:
org.mockito.exceptions.verification.TooManyActualInvocations:
mUserDbAccessor.getIn(1, 2, 3);
Wanted 1 time:
-> at ~.model.user_info.UserRepoTest.batchUserInfoUnorderedCacheMiss(UserRepoTest.java:75)
But was 2 times. Undesired invocation:
-> at ~.model.user_info.UserRepo.lambda$batchUserInfoUnordered$3(UserRepo.java:108)
这时候 mockito 的强大就体现出来了,非常简洁直观地告诉我们哪里出了什么问题:getIn 只应该调用一次,结果调用了两次!
看!我们拿到了正确的 User,但却不是按照正确的方式,以后只是经过了 QA 之手的版本,你敢信心满满地拍胸脯保证没问题?
6,问题出在哪儿?
遇见问题不可怕,只要我们有清晰缜密的思路,去寻找问题发生的原因、分析原因找出解决办法,那就好办。
不过遗憾的是,这个问题我已经知道了原因,我只是一开始不太确定,所以才亟需编写一个测例来解答我的疑惑,所以这里我没法和大家分享我解决这个问题的思路了。
问题就出在第一部分代码中的 5,6 步:我们分别对 cacheResult 进行了 map 和 flatMap,得到了两个流,但 defer 创建的是一个 cold observable,多次 subscribe(分成多个流最终就会导致多次 subscribe)就会多次执行 defer 内的代码,所以我们进行了两次数据库查询。
7,怎么解决它?
我的第一反应就是 make it hot,但用什么操作符却不确定,所以我打算 google 一下,而且我还依稀记得有个大牛分享过这种用法。
首先 query 当然是 “rxjava observable”,但可想而知结果会太泛,基本不可能搜到目标,于是加上两个词,“rxjava observable expensive cache”,描述了一下我们的场景,但搜索结果依然不理想,而且都比较早,以 14,15 年的为主。
于是我限定了 site “site:androidweekly.net data cache”,因为我还依稀记得是在 AndroidWeekly 上看到的,改了 query 是因为第一下没有结果。但依然没有找到目标。
于是我再次想了想,好像是 Dan Lew 写的文章,于是换个 site “site:danlew.net observable”,第一个结果就是苦苦追寻的:Multicasting in RxJava。而且 google 也显示我在不久前访问过它。
当然,你可能会选择查看 RxJava 手册,再次过一遍所有的操作符,并最终找到目标,不过由于我的脑海里残存了一点 Dan Lew 文章的印象,所以这种方式在我看来更快。
Observable<Pair<List<User>, long[]>> cacheResult =
Observable.defer(() -> {
// ...
})
.publish()
.autoConnect(2)
用 publish 来 make it hot,用 autoConnect 来省去我们手动调用 connect,我们知道只会有两次 subscribe,所以我们就用 autoConnect(2)。这里还有一个关键点,就是 publish 的时机,不过在我们这里不是问题,因为我们有了明确的“分水岭”。
8,测试全面了吗?
修改之后执行测试,终于通过。
但我们测试得全面吗?看似测得很深,但其实只考虑了一种情况,那就是缓存完全缺失,还有缓存完全命中、部分命中的情况根本没考虑到!
所以我们加上一个缓存全部命中的情况:
@Test
public void batchUserInfoUnorderedNoCacheMiss() {
long[] uids = new long[]{1, 2, 3};
final User user = mGson.fromJson(MOCK_USER, User.class);
// 缓存全部命中
when(mUserDbAccessor.getIn(uids))
.thenReturn(Arrays.asList(user, user, user)); // 1
UserRepo userRepo = new UserRepo(mUserInfoApi, mGson, mUserDbAccessor);
TestSubscriber<List<UserInfoModel>> testSubscriber = new TestSubscriber<>();
userRepo.batchUserInfoUnordered(uids).subscribe(testSubscriber);
testSubscriber.awaitTerminalEvent();
testSubscriber.assertNoErrors();
testSubscriber.assertCompleted();
testSubscriber.assertValue(Arrays.asList(user, user, user)); // 2
// 不会请求 api
verifyZeroInteractions(mUserInfoApi); // 3
// 不会更新 db
verify(mUserDbAccessor, times(1)).getIn(uids); // 4
verifyNoMoreInteractions(mUserDbAccessor);
}
我们这边让缓存全部命中(1),验证拿到了正确的数据(2)、没有调用 API(3)、只进行了一次数据库查询(4)。
执行测试,再次“正常地”失败了:
org.mockito.exceptions.verification.NoInteractionsWanted:
No interactions wanted here:
-> at ~.model.user_info.UserRepoTest.batchUserInfoUnorderedNoCacheMiss(UserRepoTest.java:103)
But found this interaction on mock 'mUserDbAccessor':
-> at rx.Observable$11.onNext(Observable.java:4448)
***
For your reference, here is the list of all invocations ([?] - means unverified).
1. -> at ~.model.user_info.UserRepo.lambda$batchUserInfoUnordered$3(UserRepo.java:108)
2. [?]-> at rx.Observable$11.onNext(Observable.java:4448)
我们额外调用了一次 mUserDbAccessor.put,因为我们的代码是这样写的:
Observable<List<User>> missed = cacheResult
.flatMap(pair -> {
// ...
})
.doOnNext(mUserDbAccessor::put);
无论如何我们都 put 了一次,如果缓存完全命中,网络数据是空的,那我们当然不应该调用 put!
所以我们把代码改成这样:
Observable<List<User>> missed = cacheResult
.flatMap(pair -> {
// ...
})
.doOnNext(users -> {
if (!users.isEmpty()) {
mUserDbAccessor.put(users);
}
});
再次运行测例,顺利通过。
当然,还有缓存部分命中的情况,测试逻辑类似,这里就不赘述了。
此外,这里还没有讲怎么做异步,如此复杂的情况下怎么做异步。这块内容我最近发现自己还是没有理解透彻,所以还需要再好好总结一下,敬请期待 :)
9,小结
看到这里,你是不是会觉得我挺不靠谱的?写个代码三番五次出错。
这里我一共犯了三次错误:还没想清楚就写了一部分代码,中途才停下来理清思路;cold observable 代码执行了多次(当然这一点我写的时候就意识到很可能会有问题);doOnNext 没有检查是否为空。
我当然不是圣人,Linus 才是。
但是我知道及时停下来理清思路,编写测试及时发现错误,保证代码可靠性,以及经常总结,并和大家一起分享。
这会让我向他靠近的,我确定。