今天下午修复了一个 YUV 图像翻转的问题,YUV 图像翻转其实没啥好说的,但期间碰到了一点性能问题,性能优化的过程我觉得比较有趣,所以在这里分享出来,希望对大家有帮助。
YUV 翻转
YUV 是一种图像编码格式(RGB 也是一种图像编码格式),YUV 主要用于视频,用来降低带宽。安卓平台上,用 Camera1 API 采集出来的数据(通过 PreviewCallback 回调获得)默认是 YCbCr_420_SP(简称 NV21,这是 YUV 的一种子格式)格式,NV21 的数据分布如下图所示(图片来源于 StackOverflow):

更多 YUV 格式的细节这里就不展开了,感兴趣的朋友可以查看 Wikipedia。
我们用户需要的是图像上下翻转的功能,但前同事实现成了 180° 旋转,这就导致画面左右颠倒了。
YUV 的操作其实都挺烧脑的,我每次都会画图来分析。
旋转 180° 的操作如下:
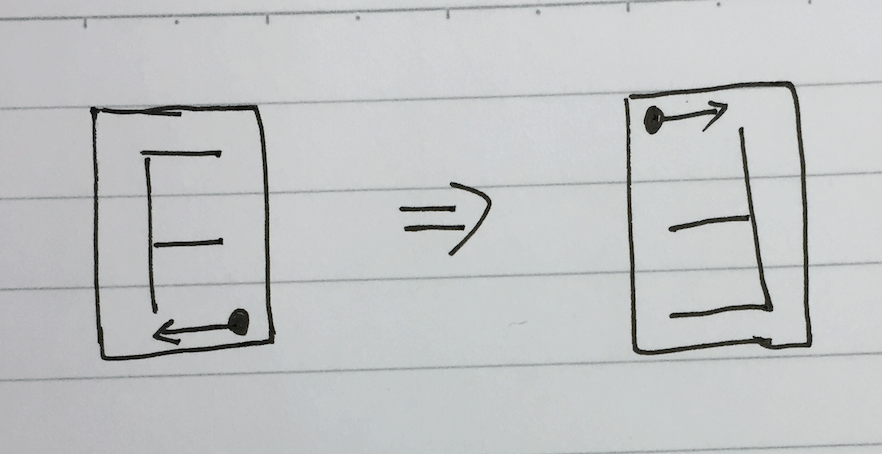
相当于要把矩阵完全逆序,代码如下:
private void flipImage(byte[] src, byte[] dst, int width, int height) {
int wh = width * height;
// Y
for (int i = 0; i < wh; i++) {
dst[i] = src[wh - i - 1];
}
// UV
for (int j = 0; j < wh / 2; j += 2) {
dst[wh + j] = src[wh + wh / 2 - j - 2];
dst[wh + j + 1] = src[wh + wh / 2 - j - 1];
}
}
其实这个操作可以就地实现,LeetCode 上也有一道要求就地旋转图像的题:Rotate Image,但这里我们就不在这一点上纠结了。
上下翻转的操作如下:
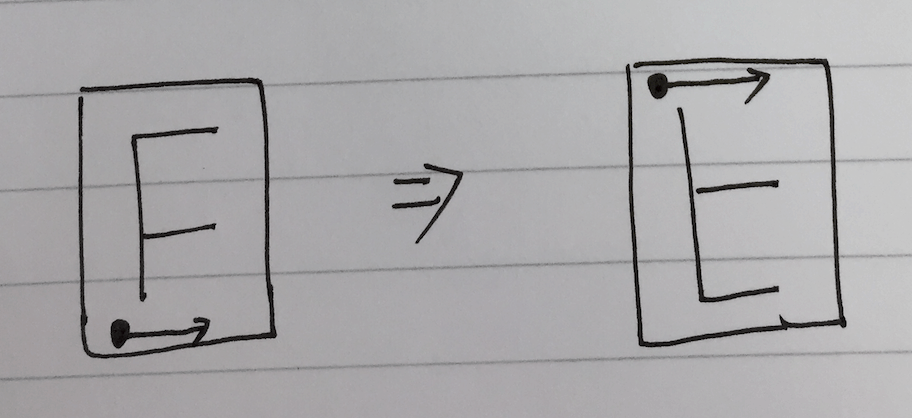
这里我们需要的是把矩阵底部的行放到顶部去,代码如下:
private void flipImageVertical(byte[] src, byte[] dst, int width, int height) {
// Y
for (int x = 0; x < width; x++) {
for (int y = 0; y < height; y++) {
dst[y * width + x] = src[(height - 1 - y) * width + x];
}
}
// UV
int wh = width * height;
int halfH = height / 2;
for (int x = 0; x < width; x += 2) {
for (int y = 0; y < halfH; y++) {
dst[wh + y * width + x] = src[wh + (halfH - 1 - y) * width + x];
dst[wh + y * width + x + 1] = src[wh + (halfH - 1 - y) * width + x + 1];
}
}
}
通常来说,测试没问题之后故事就要结束了,但这里出现了新情况:之前对这段 YUV 操作的代码加了时长统计,旋转 180° 的代码执行耗时平均 13ms,但上下翻转的代码却要 23ms,耗时多了将近一倍!
性能优化
《Unix 编程艺术》中有一条优化原则:
雕琢前先得有原型,跑之前先学会走。
先求运行,再求正确,最后求快;先测量,再优化,再测量。功能已经正确,测量结果也表明了相对严重的性能问题,那么是时候优化性能了。
优化思路一:native 化
Java 最大的特点就是简单,没有 C++ 那样海量的语言特性难以驾驭,但 Java 还有另一个特点就是性能差,同样的代码,C++ 版本的速度是 Java 版本的几倍甚至几十倍。所以遇到计算型任务的性能问题,首先想到的就是把计算转移到 native 层,这是最快的方法,往往也是效果最明显的方法。
不过遗憾的是,13ms 和 23ms 已经是 native 化之后的测试结果,所以得另寻突破口了。
这种情况下,最明显的思路就是找茬(差异)了,关于常见的解 bug 思路,可以看看我之前的文章:从 A/Looper: Could not create epoll instance. errno=24 错误浅谈解决各种 bug 的思路。
优化思路二:乘除变加减
对比两个函数,最明显的差异有两个:一层循环 v.s. 两层循环;乘除运算少 v.s. 乘除运算多。
循环层数会影响性能?咱们赋值次数都是一样的,big O 表示法连常数项都没有差异好么,怎么可能!
而显然乘除运算比加减运算要耗时,所以我决定拿乘除运算开刀,代码修改如下:
private void flipImageVertical(byte[] src, byte[] dst, int width, int height) {
// Y
int endIdx = (height - 1) * width;
for (int x = 0; x < width; x++) {
int dstIdx = x;
int srcIdx = endIdx + x;
for (int y = 0; y < height; y++) {
dst[dstIdx] = src[srcIdx];
dstIdx += width;
srcIdx -= width;
}
}
// UV
int wh = width * height;
int halfH = height / 2;
endIdx = (halfH - 1) * width;
for (int x = 0; x < width; x += 2) {
int dstIdx = wh + x;
int srcIdx = wh + endIdx + x;
for (int y = 0; y < halfH; y++) {
dst[dstIdx] = src[srcIdx];
dst[dstIdx + 1] = src[srcIdx + 1];
dstIdx += width;
srcIdx -= width;
}
}
}
就在我满心欢喜打算见证奇迹的时候,现实打了我一个响亮的耳光:22ms,几乎没差别!这我就尴尬了,难道一层循环还真的就比两层循环好?
这次很幸运,坐我对面大我十岁的贵系师兄点醒了我,省去了我上下求索的时间。
优化思路三:内存访问模式
你这每次操作之后,下标都增减 width,随机访问导致缓存缺失,性能肯定会有影响吧?
随后我再看了一眼我的代码,确实啊!和 flipImage 的代码相比,还有一个隐藏的差异:一个完全顺序访问,一个则是跳来跳去。在计算机系统里,访问内存时 CPU 都有多级缓存,而缓存都是以内存地址块为单位缓存的,也就是说,如果顺序访问,那缓存缺失一次之后,后续的访问都会命中缓存,而随机访问则意味着每次访问都会缓存缺失,那这样性能当然会大打折扣。
实际上翻转操作并不需要这样的随机访问,我们需要的是把矩阵底部的行放到顶部去,那么直接逐行拷贝即可,所以最后的代码长这样:
private void flipImageVertical(byte[] src, byte[] dst, int width, int height) {
// Y
for (int y = 0; y < height; y++) {
System.arraycopy(src, (height - 1 - y) * width, dst, y * width, width);
}
// UV
int wh = width * height;
int halfH = height / 2;
for (int y = 0; y < halfH; y++) {
System.arraycopy(src, wh + y * width, dst, wh + (halfH - 1 - y) * width, width);
}
}
拿这段 Java 代码,测量耗时就已经缩短到了 13ms,不过由于 System.arraycopy 肯定是 native 实现的,把这段代码转移到 native 层优化将不会太大。实际测量结果符合预期,native 化之后,耗时只降低到了 11ms。
后记
过去一个多月,做了很多性能优化的工作,性能优化首要的原则就是:一定要先测量,找到瓶颈,再对瓶颈做优化,优化之后也一定要记得测量验证,切忌瞎优化。
最近两周也在死磕一个非常棘手的问题:某几款机型上,停止相机预览会触发一些奇怪的错误,各种 system server 全线崩溃,甚至导致手机重启。现在问题还没有解决,待会儿还得继续,不过排查的思路还是以找差异为主,不断探索尝试,等这个问题解决了,再来和大家分享 :)