我在今年年初离开 YOLO 加入了一家在流媒体领域具有极深积累的小公司,负责视频群聊 SDK 的开发工作,YOLO 是一款直播 APP,我常戏称这是从技术下游(SDK 使用方)跑到了技术上游(SDK 提供方)。不过事情当然不是这么简单,经过长期的思考和探讨,我最终确认:实时多媒体领域,更宽泛一点来讲,实时视觉、感知的展现,在未来极长一段时间内都存在很大的需求,也存在很大的挑战,所以这将是我长期技术积累的大方向。
明确了大方向之后,就需要不懈地积累了。我一直强调基础知识的重要性,最近我就花时间学习了 H.264 的基础(《新一代视频压缩编码标准:H.264/AVC(第2版)》),力求搞清楚两个问题:H.264 编解码的过程是怎样的?H.264 码流的结构是怎样的?
以前看书后分享的只是零碎的笔记,没敢发布博客,这一篇我力求根据自己的理解,把上述两个核心问题描述清楚,细节内容篇幅有限,就不做展开了。感兴趣的朋友可以阅读原书,当然,最正宗的资料莫过于 H.264 SPEC 了。本文使用的图片基本都是摘自《新一代视频压缩编码标准:H.264/AVC(第2版)》。
视频编解码基础
视频为什么需要编码?
因为原始视频数据量太大!
以分辨率为 640x480,帧率为 30 fps 的视频为例,如果直接传输/存储原始 RGB 数据,那码率将高达 210.94 Mbps(在专业领域码率单位通常使用 bit 而非 byte),1280x720 30 fps 码率更将高达 632.81 Mbps。
640*480*3*8*30 = 210.94 Mbps(宽*高*像素字节数*字节比特数*帧数)1280*720*3*8*30 = 632.81 Mbps
这么高的码率显然不能直接使用。即便换成更节省空间的 YUV 格式,无论是通过网络传输还是磁盘存储,码率依然高得不可接受,所以必须进行编码压缩。
视频为什么可以编码?
因为视频数据存在冗余。
首先是数据冗余,图像的各个像素之间、视频的各帧之间存在着很强的相关性。比如图片中的一堵白色墙面,各个区域的像素值很接近,比如日常拍摄的视频,内容基本上都是相同的物体在不同的位置移动。
其次是视觉冗余,根据人眼的一些特性比如亮度辨别阈值、视觉阈值、对亮度和色度的敏感度不同,即便引入适量的误差,也不会被察觉出来。
视频编码有哪些主要技术?
视频编码的目标就是在尽可能压缩数据的同时,保证视频的质量。因此,视频编码的主要技术都是围绕消除冗余、提高压缩比的。当然,考虑到基于分组交换的网络环境,以及实时多媒体应用场景,视频编码也要考虑网络自适应、容错等问题。
注:下面这几段话,涉及了不少关键技术名词,没有相关背景的朋友可能会毫无概念,大家可以查阅维基百科词条了解其具体含义,关键词:预测编码,帧内预测,帧间预测,运动补偿,运动估计,运动矢量,变换编码,离散余弦变换,量化参数,熵编码,哈夫曼编码、算术编码。
预测编码与运动补偿:预测编码旨在消除视频的数据冗余,经过编码压缩后,传输的不是图像中每个像素点的实际取样值,而是预测值与实际值之差。预测编码分为帧内预测和帧间预测,分别用来消除帧内冗余和帧间冗余。为了提高效率和效果,预测编码都是针对像素块完成,而不是像素点。帧内预测就是用邻近像素块预测该像素块,帧间预测则会先在邻近帧寻找该像素块的相似块,得到两者空间位置偏移量,再进行预测。我们把计算偏移量(即寻找相似块)的过程叫做运动估计,偏移量叫做运动矢量,我们把这种描述邻近帧差别的方式叫做运动补偿。
注:这里所说的“预测”,实际上和“参考”是一个意思,就是找到被参考对象,与自己计算差异。
变换编码与量化:绝大多数图像都有一个共同特征,平坦区域和内容缓慢变化区域占据一幅图像的大部分,而细节区域和内容突变区域则占小部分,即图像中直流和低频区占大部分,高频区占小部分。因此把图像从时空域变换到频域,更利于压缩。这个变换的过程,就叫变换编码,变换方法最常用的是离散余弦变换(Discrete Cosine Transform, DCT)。变换编码之后再把变换系数映射为较小的数值,这个过程叫做量化。
熵编码:利用信源的统计特性进行码率压缩的编码就称为熵编码,也叫统计编码。高频符号赋予短码,低频符号赋予长码,即可减少整体比特数。视频编码常用的熵编码有可变长编码(Variable Length Coding, VLC,也叫哈夫曼编码)和算术编码(Binary Arithmetic Coding, BAC)。
预测编码、变换编码、熵编码这样的编码框架,其实上世纪七十年代末就已经确定了下来,直到今天尚未发布的 H.266 规范依然在用,这四十年来基本都是处于老瓶装新酒的状态,当然细节之处还是在不断进行优化的。
H.264 码流结构
我们先了解 H.264 的码流结构,以及这样设计的原因,了解了码流结构后,编解码的过程就有了具体的依托。实际上 H.264 规范也是先规定了码流结构,再规定解码器的结构(对于编码器的结构和实现模式没有具体的规定),都是同样的道理。
句法元素分层
编码器输出的码流中,数据的基本单位是句法元素(可以理解为码流结构的每一个基本字段),句法(Syntax)表征句法元素的组织结构,语义(Semantics)阐述句法元素的具体含义,所有的视频编码标准都是通过定义句法和语义来规范编码器工作流程的。
在 H.264 中,句法元素被组织成序列、图像、片、宏块(Macro Block, MB)、子块五个层次,如下图所示:
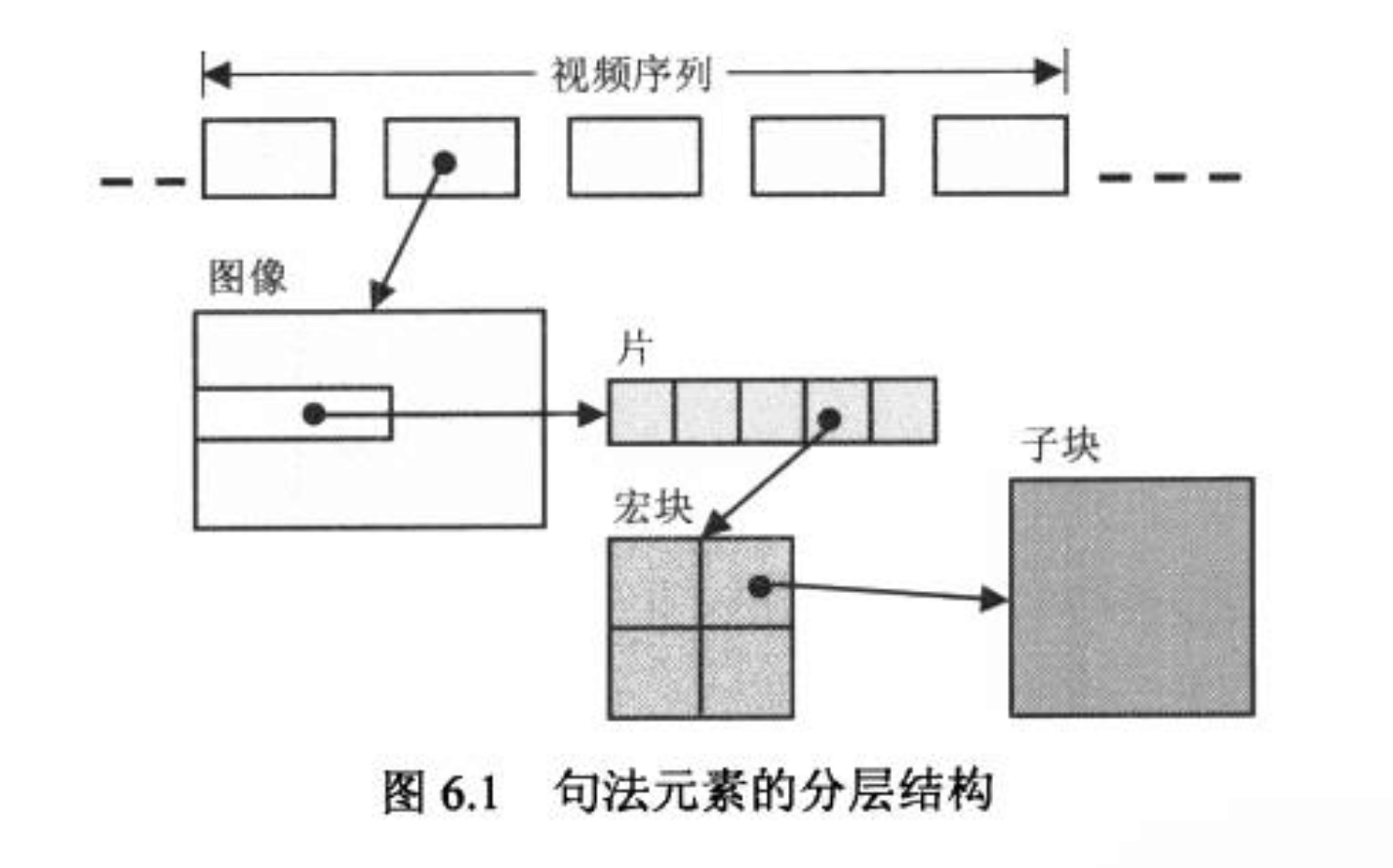
分层有利于节省码流,例如下一层中的共用信息可以在上一层保存,而不是每个下层结构都携带一份。但在 H.264 的分层结构中,各层数据组织并没有形成强依赖关系,这样有助于提高鲁棒性。因为分组交换容易出错,如果存在强依赖关系,一旦头部丢失,那后面的数据就无法使用了。
相较于以往标准,H.264 取消了序列层和图像层(概念上存在,但实际上取消了),把原本属于序列和图像头部的大部分句法元素抽离出来,形成了序列参数集(Sequence Parameter Set, SPS)和图像参数集(Picture Parameter Set, PPS),其余的句法元素则放入片层。参数集是独立的数据单位,不依赖参数集外的其他句法元素,它们可以单独传输、重点保护。
取消了序列层和图像层的分层结构及各层关系如下图所示:
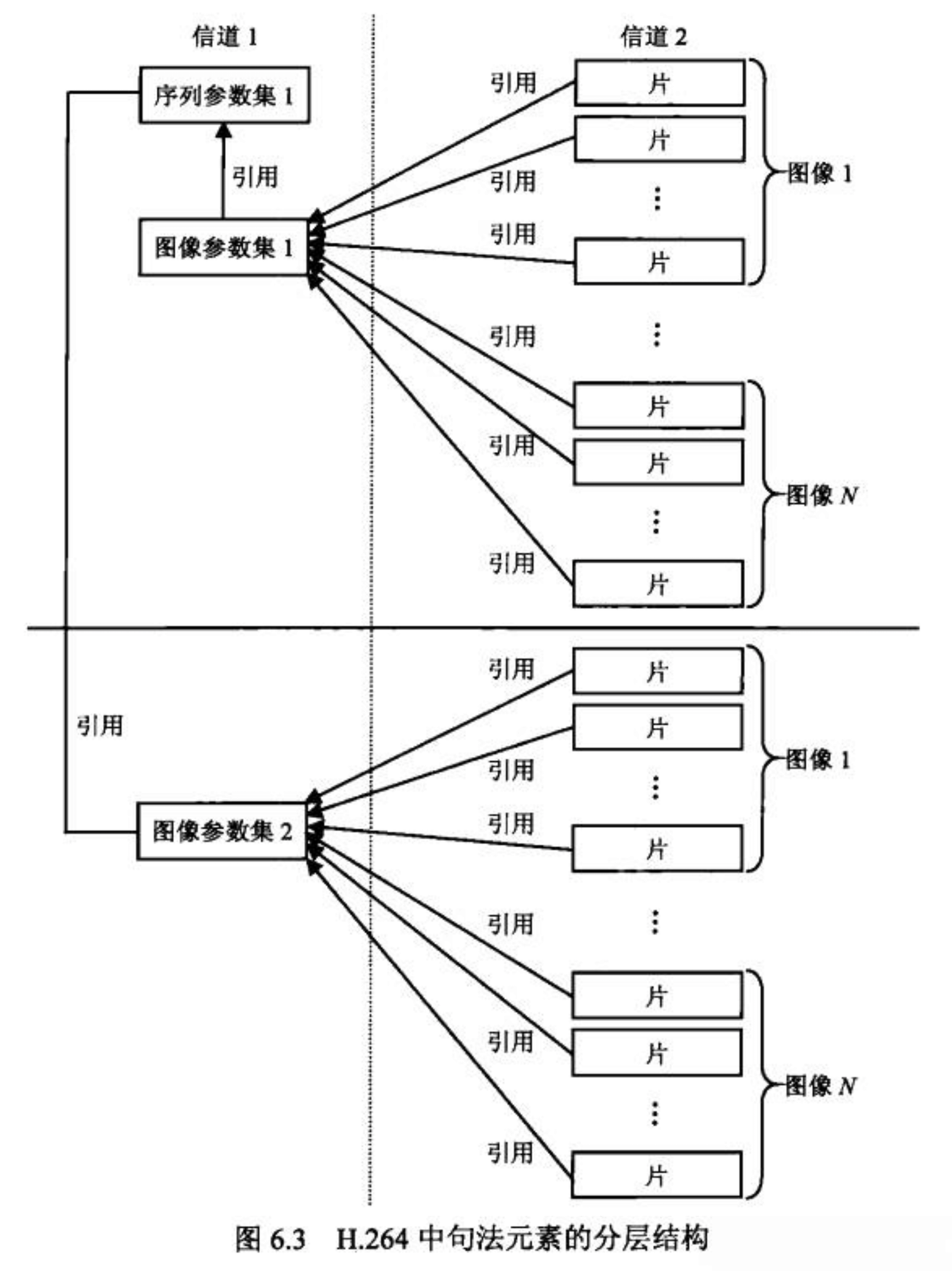
从上图中我们可以看到,一幅图像由多个片组成,片数据会引用 PPS,PPS 又会引用 SPS,而 PPS 和 SPS 可以单独传输,重点保护。
那片、宏块、子块这三层数据又是什么组织结构呢?请看下图:

skip_run:当图像采用帧间预测编码时,H.264 允许在图像平坦的区域使用“跳跃”块,“跳跃”块本身不携带任何数据,解码器通过周围已重建的宏块的数据来恢复“跳跃”块;mb_type是宏块类型,例如 I 帧的宏块,P 帧的宏块(注:关于帧类型,可以搜索相关维基词条,关键词:I 帧,P 帧,B 帧,SP 帧,SI 帧);mb_pred和sub_mb_pred是预测编码过程的预测信息,比如宏块如何划分,参考宏块的 id 等;- 残差数据(
resisual)则是预测编码过程中,预测块和本块数据之间的差值;
宏块是解码的基本单元,解码器根据预测信息和残差数据,进行解码。
功能分层
除了句法元素的分层,H.264 功能上也分为两层:视频编码层(Video Coding Layer, VCL)和网络抽象层(Network Abstraction Layer, NAL)。VCL 数据即编码处理的输出,正是它被分为了上述的五层结构。VCL 数据在传输或存储之前,会先封装进 NAL 单元,每个 NAL 单元则分为原始字节序列负荷(Raw Byte Sequence Payload, RBSP)和描述 RBSP(即 VCL 数据)的头部。
在分组交换网络传输中,NAL 单元各自独立、完整地放入一个分组,因此 NAL 单元之间无需分隔符,但在磁盘存储时,NAL 单元连续存放,必须引入起始码来分隔 NAL 单元。这个起始码就是连续的三字节数据 0x000001,如果数据需要对齐,则在起始码之前添加若干字节的 0 来填充。
为防止编码数据和起始码冲突,定义如下“防止竞争”(emulation prevention,其实就是转义)规则(00 被解码器作为 NAL 单元结束,01 被解码器作为 NAL 单元开始,03 用于转义,02 尚未使用):

编码器编码后如果检测到这些转义前序列,就在最后一个字节前插入 0x03,解码器解码时如果检测到 0x000003,就把最后的 0x03 丢弃。有了上面的转义规则后,解码器就可以把 0x000001 之后到 0x000000 之前的数据作为一个 NAL 数据单元了。
NAL 单元的结构如下图所示:
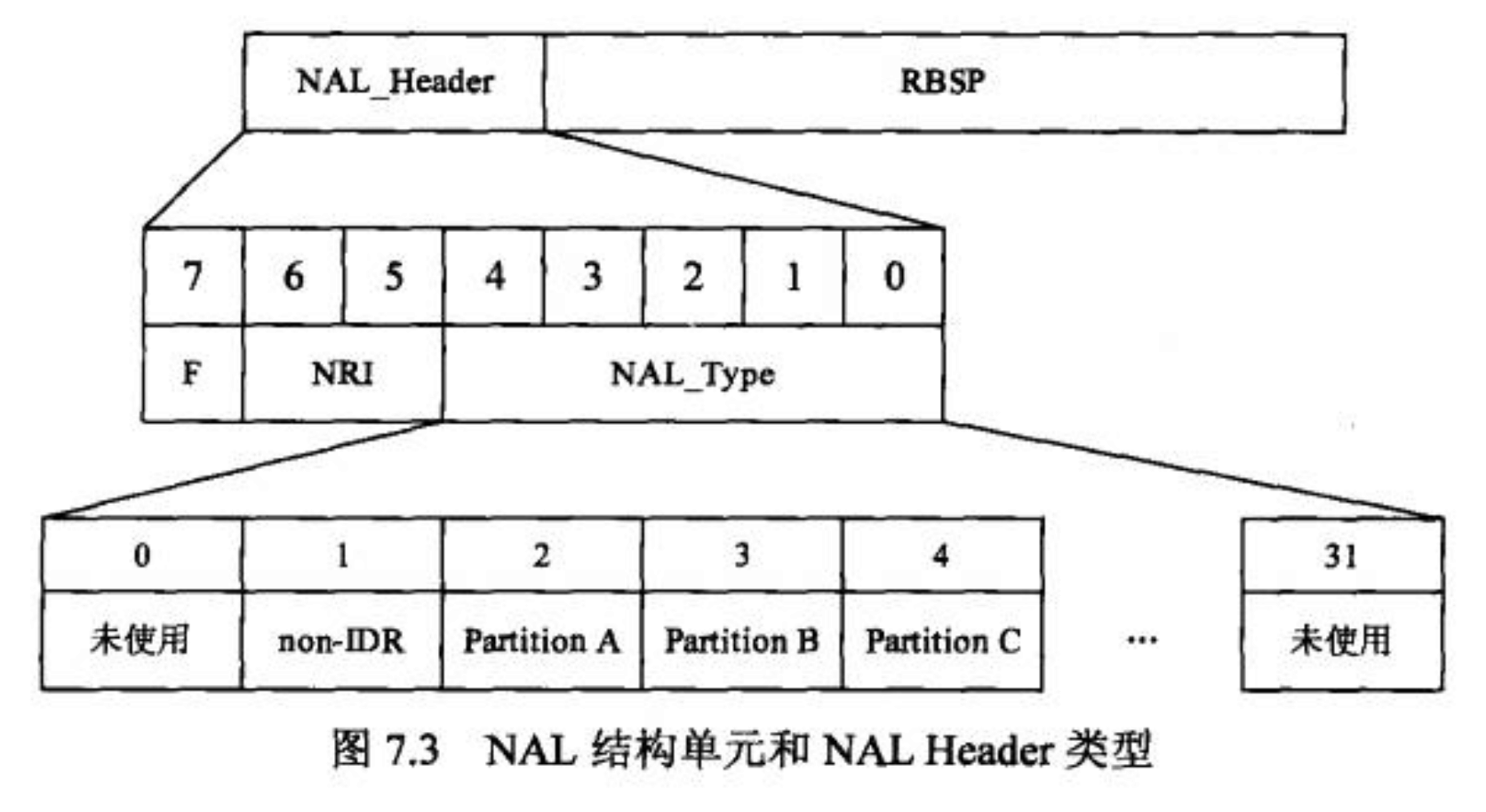
其中 NAL 类型定义如下:

从 nal_unit_type 的定义可知,编码数据传输的基本单元是片,而片内则包含了宏块和子宏块。实际上帧内预测也是局限于片内的,不同片之间是不能参考的,这样做主要就是为了在错误发生时,限制错误的影响范围。
这里我们可以总结如下:H.264 码流传输的基本单元是 NAL 单元,NAL 单元内携带的最关键的数据是参数集和片数据;解码的基本单元是宏块,解码器根据预测信息和残差数据,解码出原始数据;宏块解码之后拼接成片,片拼接成图像,而一幅幅图像则构成了视频!
这里我还想提一点,那就是最后这个一层层的拼接关系,是怎么无缝衔接起来的?
如果让我们设计方案,我们也许会为图像增加播放顺序,进而图像可以按序播放;我们也许会为片增加编号,进而各片就可以按编号拼接为一幅图像;我们也许会为宏块增加编号,这样各宏块就可以按编号拼接为一个片。
实际上 H.264 的方案和我们的朴素想法相去无几:每幅图像除了有播放顺序(Picture Order Count, POC),还有解码顺序(frame_num),因为帧间预测有双向预测,所以解码顺序可能和播放顺序不一样;每个宏块并没有编号,因为一个片的所有宏块都在一个 NAL 单元内,它们按序排列,无需额外编号;每个片没有编号,但片头内有表示本片中首个宏块在整幅图像中的位置信息(first_mb_in_slice),这样我们就知道这个片应该放在图像的什么位置,效果和编号一样;至于整个视频、每幅图像的整体信息,例如宽高信息,则在 SPS 和 PPS 中有相关字段进行描述。
具体句法和语义
原本我想把每一层的各个句法元素简略过一遍的(实际也这么做过),但奈何完全无法涵盖细节,而众多句法元素罗列一遍实在无法脱离堆砌之嫌,所以索性删了个干净。感兴趣的朋友强烈建议阅读原书,或者 H.264 SPEC,至于从事视频编解码相关工作的朋友,则一定要对句法和语义烂熟于胸了。
我整体感觉 H.264 句法描述的方式还是十分巧妙的,它以解码器伪代码的形式,来定义数据格式,真是一举两得。H.264 的句法经过了精心的设计,构成句法的各句法元素既相互依赖而又相互独立。依赖是为了减少冗余信息,提高编码效率,而独立是为了使通信更加鲁棒,在错误发生时限制错误的扩散。
H.264 编码过程
H.264 规范没有具体规定编码器的结构和实现模式,只要它产生出来的码流结构符合规范即可,这样编码过程就非常灵活了。
不过其基本结构就是第一部分我们提到的基本框架:预测编码、变换编码、熵编码。
编码器基本结构如下图所示:
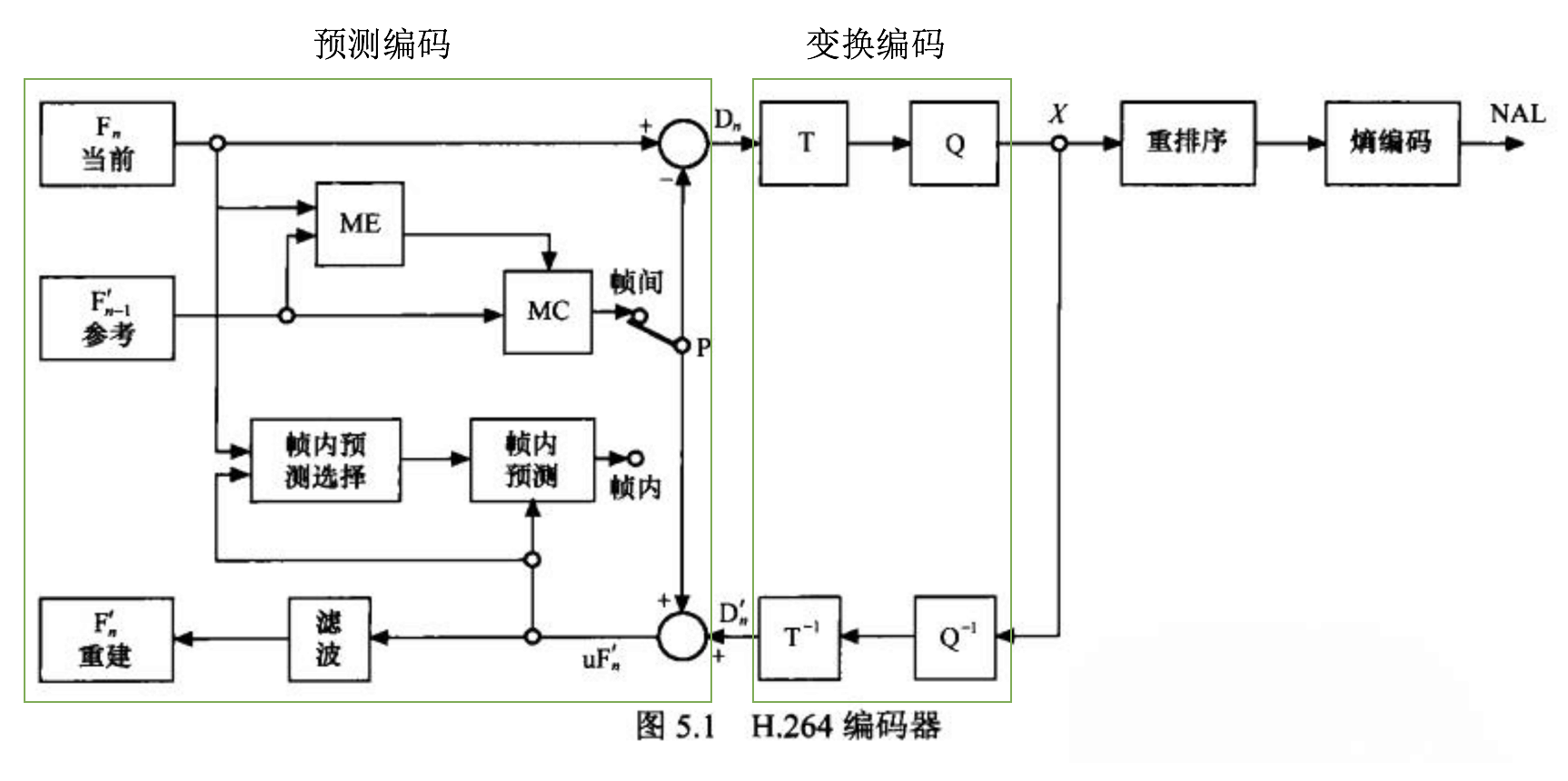
其中最复杂扩展空间最大的,就是预测编码的过程了,而预测编码里最重要同时也是最消耗计算资源的,是运动估计的搜索过程。
此外,无论编码器的结构如何,相应的视频编码的控制都是编码器实现的核心问题。在编码过程中,并没有直接控制编码数据大小的方式,只能通过调整量化过程的量化参数 QP 值间接控制,而由于 QP 和编码数据大小并没有确定的关系,所以编码器的码率控制无法做到很精细,基本都靠试。要么是中途改变后续宏块的质量,要么是重新编码改变所有宏块的质量。
H.264 解码过程
解码过程就是编码的逆过程:熵解码、变换解码、预测解码。
H.264 规范规定了解码器的结构,所以我们可以更细致的总结解码过程:以宏块为单位,依次进行熵解码、反量化、反变换,得到残差数据,再结合宏块里面的预测信息,找到已解码的被参考块,进而结合已解码被参考块和本块残差数据,得到本块的实际数据。宏块解码后,组合出片,片再组合出图像。
解码器基本结构如下图所示:

H.264 的可伸缩编码
可伸缩编码(Scalable Video Coding, SVC)实质上是将视频信息按照重要性分解,对分解的各个部分按照其自身的统计特性进行编码。一般它会将视频编码为一个基本层和一组增强层。基本层包含基本信息,可以独立解码,增强层依赖于基本层,可以对基本层的信息进行增强,增强层越多,视频信息的恢复质量也就越高。
SVC 通常有三种:
- 空域可伸缩:可以解码出多种分辨率的视频;
- 时域可伸缩:可以解码出多种帧率的视频,分辨率相同;
- 质量可伸缩:可以解码出多种码率的视频,分辨率、帧率相同;
SVC 的实现细节这里不做展开,感兴趣的朋友可以查阅相关资料。
总结
本文中我尝试解答 H.264 编解码最核心的两个问题:H.264 编解码的过程是怎样的?H.264 码流的结构是怎样的?
限于篇幅,本文无法把涉及到的概念都描述清楚,没有相关基础的读者需要查阅很多专业资料,而有相关基础的读者其实未必需要这样一篇总结文章,因此本文对于我梳理自己的思路意义更大,敬请谅解。
最后,在 AI 浪潮下,视频编解码肯定也能和 AI 结合,在视频编解码的过程中,我认为至少以下几个环节 AI 可以发挥很大的作用:
- 运动估计过程中,搜索策略的选择,应该是 AI 能否发挥作用的环节;
- 自适应分块,AI 可以对图像预处理,分析出图像细节分布;
- 编码控制:基于场景、内容,选择编码策略,AI 也可发挥很大价值;
欢迎大家加入 Hack WebRTC 星球,和我一起钻研 WebRTC。